Serenity BDD (previously known as Thucydides) is an open source reporting library that helps you write better structured, more maintainable automated acceptance criteria, and also produces rich meaningful test reports (or "living documentation") that not only report on the test results, but also what features have been tested. In this article, we will continue our exploration of Serenity, and see how it works with the popular BDD tool Cucumber-JVM.
In the previous article we looked at how you could use Serenity BDD with JUnit to write clean, readable automated acceptance tests, and how Serenity also helps you write WebDriver-based automated web tests that are easier to understand and to maintain. We will be using the same domain example in this article as we did in the previous one, but we will be going over the basics again, so you can jump straight into this article even if you haven’t read the previous one.
1. BDD fundamentals
Behaviour Driven Development, which is a core concept underlying many of Serenity’s features. A team using Behaviour Driven Development use conversations and collaboration around concrete examples to build up a shared understanding of the features they are supposed to build. Conversations about concrete examples, and counter-examples, are a great way to flush out any hidden assumptions or misunderstandings about what a feature needs to do.
Suppose you are building a site where artists and craftspeople can sell their good online. One important feature for such a site would be the search feature. You might express this feature using a story-card format commonly used in agile projects like this:
In order to find items that I would like to purchase As a potential buyer I want to be able to search for items containing certain words
To build up a shared understanding of this requirement, you could talk through a few concrete examples. The converstaion might go something like this:
-
"So give me an example of how a search might work."
-
"Well, if I search for wool, then I should see only woolen products."
-
"Sound’s simple enough. Are there any other variations on the search feature that would produce different outcomes?"
-
"Well, I could also filter the search results; for example, I could look for only handmade woolen products."
-
"So you can filter by handmade items. Could you give me some examples of other product types you would want to filter by?"
And so on. In practice, many of the examples that get discussed become "acceptance criteria" for the features. And many of these acceptance criteria become automated acceptance tests. Automating acceptence tests provides valuable feedback to the whole team, as these tests, unlike unit and integrationt tests, are typically expressed in business terms, and can be easily understood by non-developers. And, as we will see later on in this article, the reports that are produced when these tests are executed give a clear picture of the state of the application.
2. Writing acceptance criteria with Cucumber-JVM
Cucumber is a popular BDD test automation tool. Cucumber-JVM is the Java implementation of Cucumber, and is what we will be focusing on in this article. In Cucumber, you express acceptance criteria in a natural, human-readable form. For example, we could write the "wool scarf" example mentioned above like this:
Given I want to buy a wool scarf
When I search for items containing 'wool'
Then I should only see items related to 'wool'This format is known as Gherkin, and is widely used in Cucumber and other Cucumber-based BDD tools such as SpecFlow (for .NET) and Behave (for Python). Gherkin is a flexible, highly readable format that can be written collaboratively with product owners to ensure that everyone . The loosely-structured Given-When-Then format helps people focus on what they are trying to achieve, and how they will know when they get it.
Sometimes tables can be used to summarize several different examples of the same scenario. In Gherkin, you can use example tables to do this. For instance, the following scenario illustrates how you can search for different types of products made of different materials:
Scenario Outline: Filter by different item types
Given I have searched for items containing '<material>'
When I filter results by type '<type>'
Then I should only see items containing '<material>' of type '<type>'
Examples:
| material | type |
| silk | Handmade |
| bronze | Vintage |
| wool | Craft Supplies |In this article, we will learn how to automated these scenarios using Cucumber and Serenity BDD. Don’t worry if you haven’t used Cucumber before, as we will go through enough examples for you to see how it works even if you are new to BDD test automation tools.
3. Writing executable specifications with Cucumber and Serenity
3.1. Writing the scenario
Let’s start off with the first example discussed above. In Cucumber, scenarios are stored in Feature Files, which contain an overall description of a feature as well as a number of scenarios.. The Feature File for the example above is called search_by_keyword.feature, and looks something like this like this:
Feature: Searching by keyword
In order to find items that I would like to purchase
As a potential buyer
I want to be able to search for items containing certain words
Scenario: Should list items related to a specified keyword
Given I want to buy a wool scarf
When I search for items containing 'wool'
Then I should only see items related to 'wool'These feature files can be placed in different locations, but you can reduce the amount of configuration you need to do with Serenity if you put them in the src/test/resources/features directory.
You typically organize the feature files in sub-directories that reflect the higher-level requirements. In the following directory structure, for example, we have feature definitions for several higher-level features: search and shopping_cart:
|----src | |----test | | |----resources | | | |----features | | | | |----search | | | | | |----search_by_keyword.feature | | | | |----shopping_cart | | | | | |----adding_items_to_the_shopping_cart.feature
3.2. The Scenario Runner
Cucumber runs the feature files via JUnit, and needs a dedicated test runner class to actually run the feature files. When you run the tests with Serenity, you use the CucumberWithSerenity test runner. If the feature files are not in the same package as the test runner class, you also need to use the @CucumberOptions class to provide the root directory where the feature files can be found. The test runner to run all of the feature files looks like this:
package net.serenity_bdd.samples.etsy.features;
import cucumber.api.CucumberOptions;
import net.serenitybdd.cucumber.CucumberWithSerenity;
import org.junit.runner.RunWith;
@RunWith(CucumberWithSerenity.class)
@CucumberOptions(features="src/test/resources/features")
public class AcceptanceTests {}3.3. Step definitions
In Cucumber, each line of the Gherkin scenario maps to a method in a Java class, known as a Step Definition. These use annotations like @Given, @When and @Then match lines in the scenario to Java methods. You define simple regular expressions to indicate parameters that will be passed into the methods:
public class SearchByKeywordStepDefinitions {
@Steps
BuyerSteps buyer;
@Given("I want to buy (.*)")
public void buyerWantsToBuy(String article) {
buyer.opens_etsy_home_page();
}
@When("I search for items containing '(.*)'")
public void searchByKeyword(String keyword) {
buyer.searches_for_items_containing(keyword);
}
@Then("I should only see items related to '(.*)'")
public void resultsForACategoryAndKeywordInARegion(String keyword) {
buyer.should_see_items_related_to(keyword);
}
}These step definitions use Serenity to organize the step definition code into more reusable components. The @Steps annotation tells Serenity that this variable is a Step Library. In Serenity, we use Step Libraries to add a layer of abstraction between the "what" and the "how" of our acceptance tests. The Cucumber step definitions describe "what" the acceptance test is doing, in fairly implementation-neutral, business-friendly terms. So we say "searches for items containing 'wool", not "enters 'wool' into the search field and clicks on the search button". This layered approach makes the tests both easier to understand and to maintain, and helps build up a great library of reusable business-level steps that we can use in other tests. Without this kind of layered approach, step definitions tend to become very technical very quickly, which limits reuse and makes them harder to understand and maintain.
Step definition files need to go in or underneath the package containing the scenario runners:
|----src | |----test | | |----java | | | |----net | | | | |----serenity_bdd | | | | | |----samples | | | | | | |----etsy | | | | | | | |----features (1) | | | | | | | | |----AcceptanceTests.java (2) | | | | | | | | |----steps (3) | | | | | | | | | |----SearchByKeywordStepDefinitions.java | | | | | | | | | |----serenity (4) | | | | | | | | | | |----BuyerSteps.java
| 1 | The scenario runner package |
| 2 | A scenario runner |
| 3 | Step definitions for the scenario runners |
| 4 | Serenity Step Libraries are placed in a different sub-package |
3.4. The Serenity Step Libraries
A Serenity Step Library is just an ordinary Java class, with methods annotated with the @Step annotation, as shown here:
public class BuyerSteps {
HomePage homePage; (1)
SearchResultsPage searchResultsPage;
@Step (2)
public void opens_etsy_home_page() {
homePage.open();
}
@Step
public void searches_for_items_containing(String keywords) {
homePage.searchFor(keywords);
}
@Step
public void should_see_items_related_to(String keywords) {
List<String> resultTitles = searchResultsPage.getResultTitles();
resultTitles.stream().forEach(title -> assertThat(title.contains(keywords)));
}
}
//end:tail| 1 | Step libraries often use Page Objects, which are automatically instantiated |
| 2 | The @Step annotation indicates a method that will appear as a step in the test reports |
These step definitions implement the "what" behind the "how" of the Given-When-Then" steps. However, like any well-written code, step definitions should not be overly complex, and should focus on working at a single level of abstraction. Step definitions typically orchestrate calls to more technical layers such as web services, databases, or WebDriver page objects. For example, in automated web tests like this one, the step library methods do not call WebDriver directly, but rather they typically interact with Page Objects.
3.5. The Page Objects
Page Objects encapsulate how a test interacts with a particular web page. They hide the WebDriver implementation details about how elements on a page are accessed and manipulated behind more business-friendly methods. Like steps, Page Objects are reusable components that make the tests easier to understand and to maintain.
Serenity automatically instantiates Page Objects for you, and injects the current WebDriver instance. All you need to worry about is the WebDriver code that interacts with the page. And Serenity provides a few shortcuts to make this easier as well. For example, here is the page object for the Home page:
@DefaultUrl("http://www.etsy.com") (1)
public class HomePage extends PageObject { (2)
@FindBy(css = "button[value='Search']")
WebElement searchButton;
public void searchFor(String keywords) {
$("#search-query").sendKeys(keywords); (3)
searchButton.click(); (4)
}
}| 1 | What URL should be used by default when we call the open() method |
| 2 | A Serenity Page Object must extend the PageObject class |
| 3 | You can use the $ method to access elements directly using CSS or XPath expressions |
| 4 | Or you may use a member variable annotated with the @FindBy annotation |
And here is the second page object we use:
public class SearchResultsPage extends PageObject {
@FindBy(css=".listing-card")
List<WebElement> listingCards;
public List<String> getResultTitles() {
return listingCards.stream()
.map(element -> element.getText())
.collect(Collectors.toList());
}
}
// end:tail[]In both cases, we are hiding the WebDriver implementation of how we access the page elements inside the page object methods. This makes the code both easier to read and reduces the places you need to change if a page is modified.
4. Reporting and Living Documentation
Reporting is one of Serenity’s fortes. Serenity not only reports on whether a test passes or fails, but documents what it did, in a step-by-step narrative format that inculdes test data and screenshots for web tests. For example, the following page illustrates the test results for our first acceptance criteria:
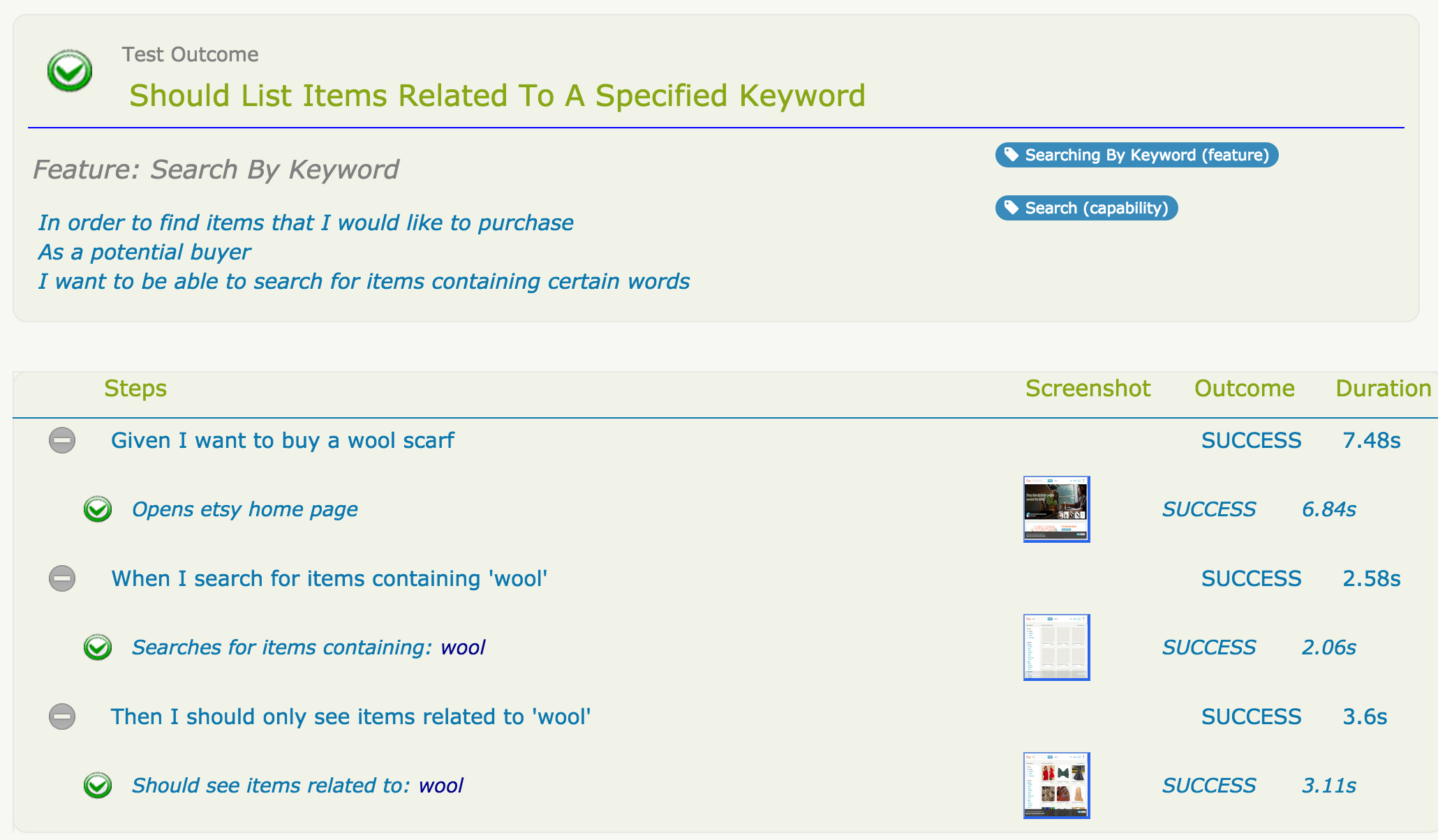
Notice how this report faithfully reproduces the example from the conversation with the business, and also gives the option of stepping into the "what", to see how a particular step has been implemented, and (in this case) what the corresponding screen shots look like.
We saw preivously how example tables can be a great way to summarize business logic; it is important for these tables to be reflected in the test results, as illustrated here:
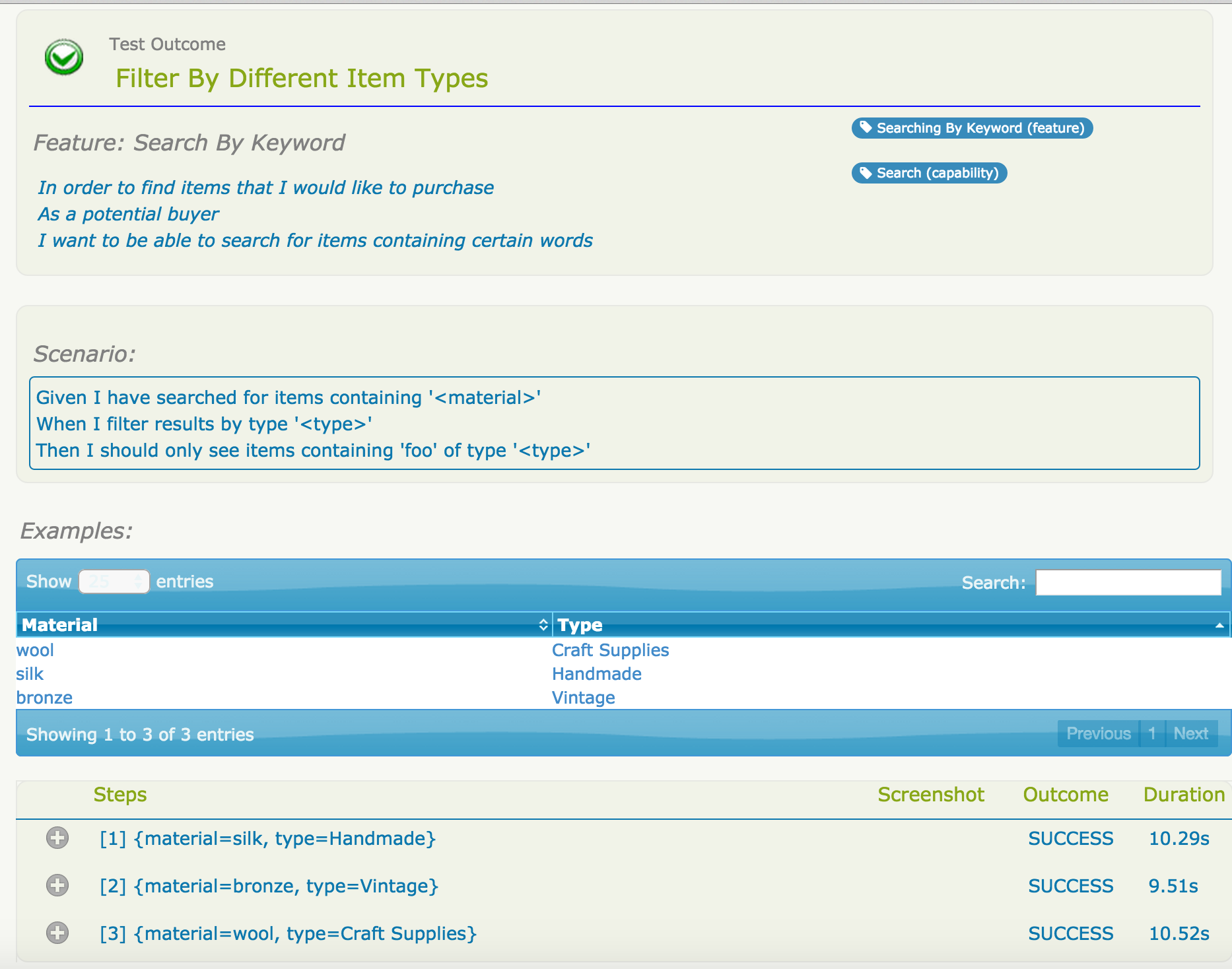
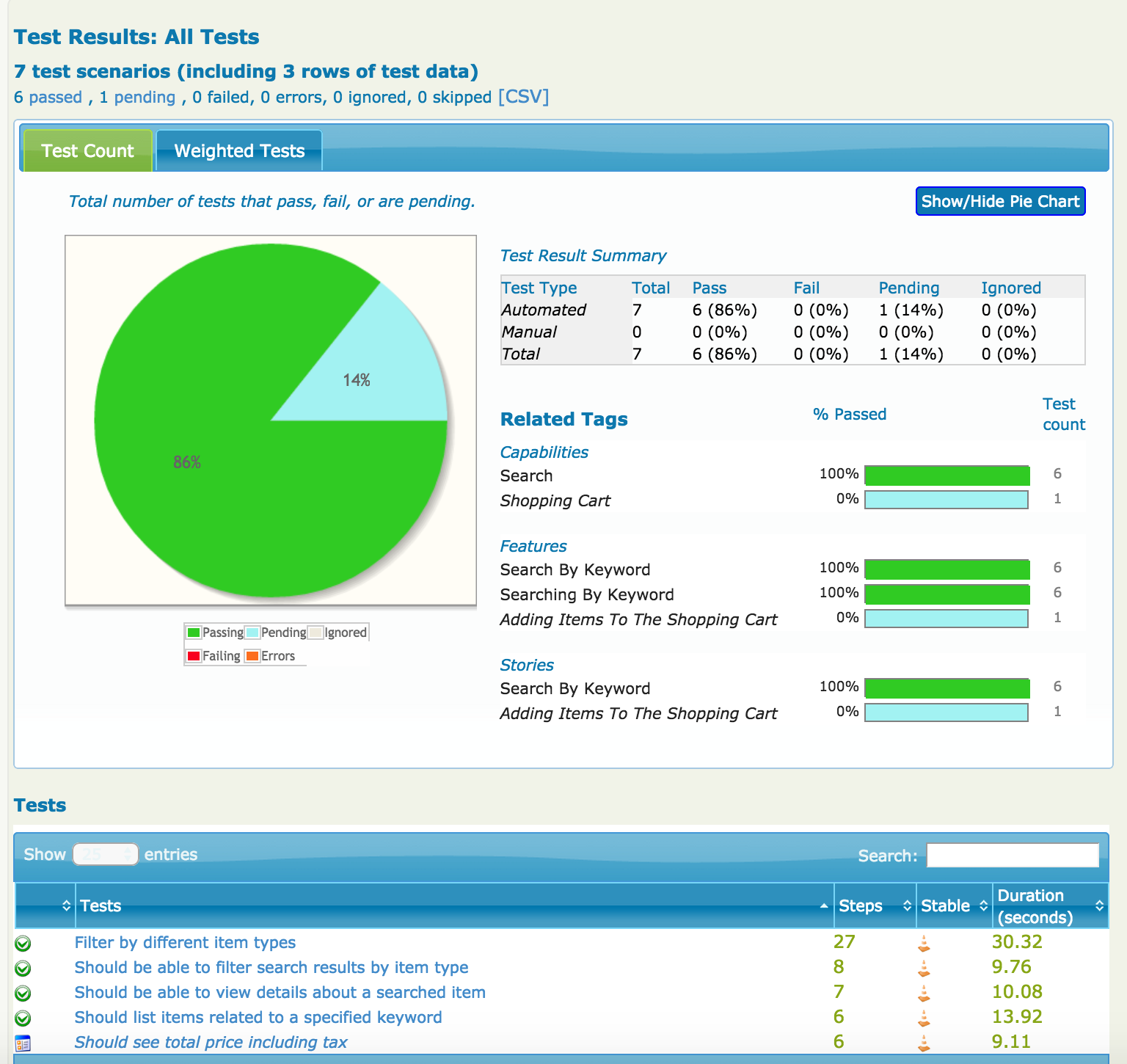
But test outcomes are only part of the picture. It is also important to know what work has been done, and what is work in progress. When you are using Cucumber, any scenario that contains steps without matching step definition methods will appear in the reports as Pending (blue in the graphs):
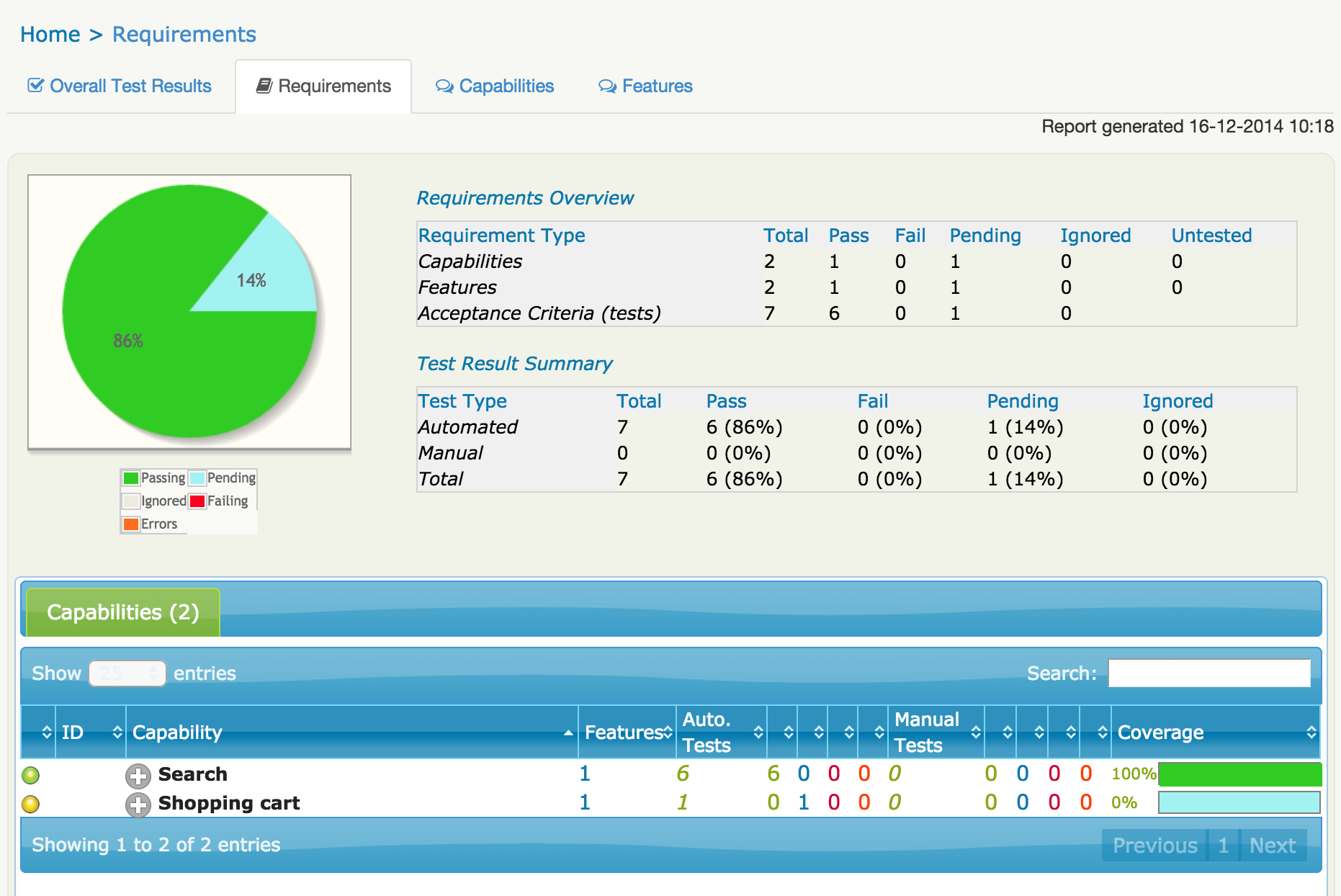
In the previous section, we saw how the feature files were organized into directories that represent higher-level features or capabilities. Serenity will use this package structure to group and aggregate the test results for each feature. This way, Serenity can report about how well each requirement has been tested, and will also tell you about the requirements that have not been tested:
5. Conclusion
Hopefully this will be enough to give you a taste of Serenity and Cucumber-JVM.
That said, we have barely scratched the surface of what Serenity can do for your automated acceptance tests. You can read more about Serenity, and the principles behind it, by reading the Users Manual, or by reading BDD in Action, which devotes several chapters to these practices. And be sure to check out the online courses at Parleys.
You can get the source code for the project discussed in this article on GitHub.